讲设备树的文章不少。以下是一些挺有意思的文章:
- 蜗窝科技的博客紧扣Linux内核来讲设备树的来历与用法;
- Thomas Petazzoni是Bootlin公司(以前叫Free Electrons,一家很有水平的专注Linux的法国公司)的CTO,他写过一份讲义叫《傻瓜都懂的设备树》,详细地介绍了设备树的语法与Linux内核中现实的用例;
- device tree kernel internals这篇报告更加详细地描述了设备树的语法、编译过程,并分析了设备树展开过程的一些源码;
- 还是Thomas Petazzoni,他在2015年的ELC会议上抱怨说:不同内核里设备树接口要保持可移植性,这简直是个神话;
很多介绍设备树的文章都会开门见山地介绍设备树的各种概念,然后罗列出设备树的语法。不过很少有人会从头到尾讲透驱动程序和设备树,然后旗帜鲜明地指出,设备树描述的就是平台设备(platform_device),或许他们默认了你已经懂得那些前提知识。以下记录了我的一些思考,尝试从面向对象的角度去切入。
C语言实现面向对象的概念
“面向对象”与其说是一种程序设计方法(方法论),不如说是一种思维(世界观)。我的一位老师粗略估计了一下:如果你用面向过程的思维去写代码维护代码,顶多能弄50万行;而用面向对象的思维的话,还不知道上限是多少。Windows XP泄露出来的源码就有4500万行了,前段时间泄露出来的Win10源码大小有12TB,一般人下下来都存不下。
如今Linux内核也有接近2000万行代码,uboot都有80万行代码了,而它们都用C语言写成,想必是用了不同于面向过程的思维和技巧了。
C语言可以实现相当多的面向对象的概念,有相当多的书籍讲述了object oriented C(OOC),关键就是使用struct去封装成员对象和函数指针,函数指针就是方法;指针很自由,可以表达各种概念。其中,Object-oriented Programming With ANSI-C这本书里的实现方法相当优雅,它并不局限于struct,而且它将void指针玩出花来了,可以说离仅使用基本面向对象语法的C++就差个class关键字了。
封装
声明一个struct就是声明一个类。定义一个struct就是将类实例化为对象。
一个类里面声明有属性和方法。使用struct的话,属性就照常写,方法就写为函数指针。比方说在一个头文件里声明foo类,里面有一个成员叫bar,然后有一个方法get_bar,返回实际对象里的bar值:
struct foo {
// 属性
int bar;
// 接口
int (*get_bar)(struct foo*);
};
get_bar()函数一般在某一个C文件里实现为static函数:
static int my_get_bar(struct foo* f)
{
return f->bar;
}
然后,在同一个C文件里面实现全局可见的构造函数:
struct foo* new_foo(void)
{
struct foo* f = (struct foo*)
malloc(sizeof(struct foo));
if (!f)
return NULL;
// 然后可有一些默认初始化
f->bar = 0;
// 还要初始化接口函数指针!
f->get_bar = my_get_bar;
return f;
}
最后,这样使用这个类:
// new一个对象:
struct foo* f = new_foo();
// 通过接口访问该对象
int the_bar = f->get_bar(f);
// 删除这个对象
free(f);
上述的实现方法展示了最基础的类的封装。接口除了基本的getter和setter之外,构造函数和析构函数也可以定义为函数指针。这时候可以写出通用的new和delete函数统一管理所有的类。Linux内核里有多种宏可以达到new和delete的目的,比方说可以通过MODULE_init()宏修饰构造函数,通过MODULE_exit()宏修饰析构函数。
封装不仅仅是属性和方法的整合,还包括要数据隐藏:只能通过一些接口来访问一个对象的属性。鉴于C语言缺乏private等语法,数据隐藏有以下方法:
- 像上面提到的OO ANSI-C那本书那样使用void指针。void指针也称自由指针,这样的话struct里面的东西就完全private了,只能通过接口来访问。
- 或者,靠程序员的自律(Linux内核就是这样干的)
继承
(继承也称泛化。“A泛化为B”,跟“B继承了A”是一个意思。)
现在假设另一个类foo2继承了foo,可以这样声明:
struct foo2 {
struct foo *super;
};
然后foo2的构造函数如下:
struct foo2 *new_foo2(void)
{
struct foo2 *f2 = (struct foo2)
malloc(sizeof(struct foo2));
if (!f2)
return NULL;
// 构造父类
f2->super = new_foo();
if (!f2->super) {
free(f2);
return NULL;
}
return f2;
}
如果需要访问foo2继承自foo的属性,则通过foo2->super的接口来访问。也可以在foo2里面重新造轮子,先做一些自己的东西,然后再调用super的方法(Linux内核里面经常这样做)。
可见,要实现继承,一般在子类里面定义一个父类(或它的指针)。如果是多继承,那就多构造几个父类。值得注意的是,要逐个构造不同的类时,只要有一个类没有成功构造,之前所成功构造的类都得析构。这样的话会写得很麻烦,于是Linux内核推荐使用goto语句:
struct f1 *f1 = new_f1();
if (!f1) goto NULL_F1;
struct f2 *f2 = new_f2();
if (!f2) goto NULL_F2;
struct f3 *f3 = new_f3();
if (!f3) goto NULL_F3;
...
// 成功
return foobar;
// 各种程度的失败
NULL_F3:
free(f2);
NULL_F2:
free(f1);
NULL_F1:
return NULL;
多态
因为使用了函数指针,指针非常自由,因而可以将其替换为任何合适的函数。于是子类可以重写(overridding)父类的方法,这体现了多态。
重载(overloading)是一种语言特性,然而C语言并不能提供这种特性,所以在需要重载的地方使用多个函数。比方说Linux的wait3()、wait4()等一系列wait系统调用,wait3表示它有3个参数,wait4表示它有4个参数。。。
举个例子:内核中STM32的串口驱动
其实不只是STM32,其他片子的串口都实现为一个tty驱动。tty不只有串口终端,还有framebuffer终端、网络终端等等,它们都统一为一个相当复杂的tty架构,不过下面仅简单探讨一些类的继承关系。
它涉及到tty_driver、uart_port、stm32_port这3个类,它们这样定义:
struct tty_driver {
...
const struct tty_operations *ops;
...
};
struct uart_port {
...
const struct uart_ops *ops;
...
struct tty_driver *tty_driver;
};
drivers/tty/serial/stm32-usart.h
struct stm32_port {
struct uart_port port;
...
};
其中,tty_operations和uart_ops都是函数指针表。从上面代码片段可以看出,uart_port继承了tty_driver,stm32_port继承了uart_port。
值得注意的是,tty_operations里的函数,不实现在tty相关的c文件里,而实现在serial相关的c文件里;uart_port的函数,不实现在serial相关c文件里,而实现在每一个芯片的串口驱动的c文件里面。这说明前两个类是抽象类。
假设我们要发送数据。tty_operations里有个write(),drivers/tty/serial/serial_core.c里将其实现为uart_write();它将数据填入缓冲区后,最终调用了uart_ops的start_tx(),drivers/tty/serial/stm32-usart.c里将其实现为stm32_start_tx(),最终依靠DMA或者轮询(polling IO)的方式将数据写入串口数据寄存器中。
还应注意到的是,它们构造父类的风格并不统一:uart_port想要继承tty_driver,则通过alloc_tty_driver()来new一个父类,然后tty_set_operations()等建立与父类的联系,最后tty_register_driver()注册驱动函数。而stm32_port要继承uart_port就直接在子类内部定义一个父类对象就完事了。
container-of()
写驱动时常需要继承一些已有的类,比方说一个字符设备驱动继承cdev,或者如1.4的例子stm32串口设备继承uart_port。C语言里父类定义在子类内部,而内核的基础设施传参时只将父类对象的指针传进来,但是驱动程序要用到的又是子类对象。所以问题就是,如何通过父类对象找到子类对象。
有一个解决办法是,将父类定义为子类的第一个成员,这样的话就可以通过强制类型转换,直接得到子类。比如:
struct son {
struct father father;
...
};
如果有一个指针struct father *f,而且知道它肯定是被继承为son的对象,那么这个指针可以强转为struct son*指针。
但是多继承的情况就无法这样做了;而且只能将父类定义为第一个成员,简直太死板了。于是Linux内核里面定义了一个contailer_of()宏,通过结构体成员的地址找到整个结构体的地址。定义在include/linux/kernel.h:
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
((type *)(__mptr - offsetof(type, member))); })
意思是,该成员的地址减去其在结构体中的偏移量,就是包含它的那个结构体的地址。其中offsetof()宏定义在include/linux/stddef.h:
#ifdef __compiler_offsetof
#define offsetof(TYPE, MEMBER) __compiler_offsetof(TYPE, MEMBER)
#else
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#endif
gcc预定义了__compiler_offsetof()宏,可以直接用。如果编译器没有这个手段的话,那么就将其定义为在0地址处的那个结构体的那个成员的偏移量。。。
值得一提的是,gcc对C语言做了大量的扩展,比方说它允许花括号括着的块结构有返回值:注意到那个圆括号花括号的组合({...}),返回的是块结构中最后一句话的返回值。另外它还允许在块结构中定义函数,于是gcc的C语言可以神奇地写出lamda函数。。。
Linux设备驱动模型
在2.5版本的内核中集中精力重新设计了设备驱动程序的架构,提出了一个精心设计的设备模型。想要实现的效果便是:如果内核发现一个设备,而且内核中有其驱动,那么内核就可以把该设备暴露到用户空间中,以待应用程序操作。而且引入sysfs,并以kobj作为sysfs里面每个对象的基类。
著名的设备、驱动、总线三剑客
外设通过总线挂到CPU上,整个系统看上去长这样(图自essential linux device drivers):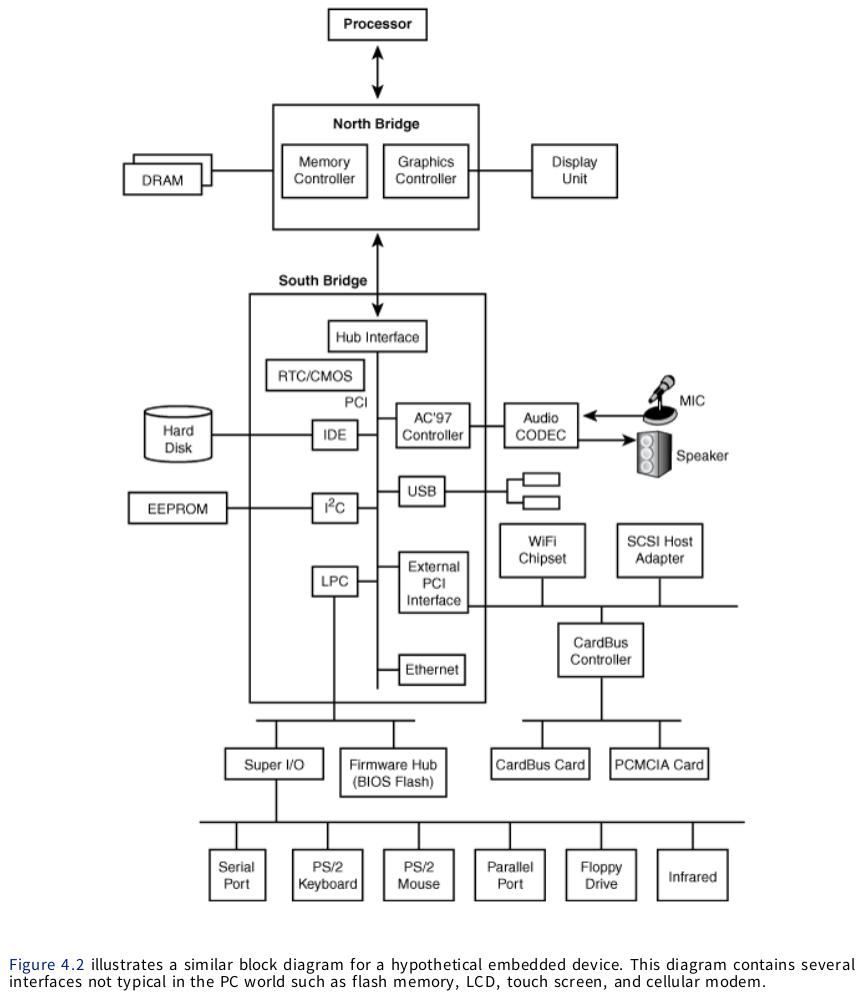
经过抽象,引入device、device_driver、bus_type这三个类;现实世界中device通过bus挂载到CPU上,device通过bus_type与device_driver联系起来。它们都声明在include/linux/device.h中:
struct device {
...
struct bus_type *bus;
struct device_driver *driver;
...
};
struct device_driver {
...
/* 一堆函数指针 */
...
};
struct bus_type {
...
/* 一堆函数指针 */
...
};
这三个类中最为复杂的是device类,另外两个类基本上是一些方法。下面罗列了它们一些简单的特性:
- device_driver和device都会注册到一个bus上。bus_type里面最重要的方法是
match(),如果判断设备和驱动相匹配,将调用device_driver的probe()方法,交给device_driver来完成接下来的工作。 - device_driver里的
probe()方法也被称为驱动程序的入口,probe成功后设备将有一系列file_operations从而可以被应用程序访问,此时设备的实例就产生了。 - device内有device指针和链表,让device之间形成一个树状结构去模拟现实系统中的情况;
- device又有kobject,通过kobj的指针在sysfs里又形成一个树状结构;
- device里还有of_node,对应到设备树上的节点。这又是一个树状结构;
- device内有个struct class*,为了方便在sysfs将设备归类。
device类集中了设备的属性,device_driver、bus_type等类集中了设备的操作;从面向对象的角度可以有数种解读,比如:
- device、device_driver、bus_type是相互独立的类;其中device依赖bus_type,device和device_driver之间是关联关系。这是一种合乎常理的理解,很多资料也从这个角度理解。
- device是以device_driver、bus_type等为父类的多继承。要实例化一个device,先实例化父类driver和bus。这也是一个合理的解读角度。
平台设备、平台驱动、平台总线
PC上的设备大都接在PCI一类的总线上,可动态探索设备、动态分配地址空间、动态分配中断资源。这时总线的处理程序就可以动态生成device来与driver配对了。
但是对于像ARM这种将内存空间和设备空间统一编址的架构来说,很多设备并不挂载在可以动态探知设备的总线上,而是有固定的地址供CPU寻址。STM32所有外设都这样(当然也有不少ARM架构的SOC有PCI总线)。这些设备都叫平台设备(platform device)。为符合Linux设备模型,就专门造出了一个虚拟的总线叫平台总线(platform bus),上面注册有平台设备与平台驱动(platform driver)。它们分别继承自device、bus_type、device_driver。
由于平台设备不能动态探知,所以内核应该事先知道这些设备,于是platform_device对象应该写死在内核里面。2.6.x内核里面就是这样干的。所以当年如果你要实现一个驱动,除了要实现platform_driver,还要在某一个地方定义一个static的platform_device(或者继承它的子类),然后在使用MODULE_init()宏修饰的构造函数里面注册driver和device(MODULE_init的工作方式是将一堆函数指针存到某一个section里,形成一个数组,以便内核初始化时候逐个调用)。
平台总线的match()方法,对比的是平台设备和平台驱动的name字段是否相同,以此来配对设备和驱动。比方说,我在一个地方定义一个设备:
static struct platform_device
foo_device = {
.name = "foo",
...
};
然后在另一个地方定义一个驱动:
static struct platform_driver
foo_driver = {
.driver = {
.name = "foo",
};
.probe = foo_probe,
...
};
在构造函数里面注册设备和驱动:
// 在一个地方添加设备
platform_add_devices(&foo_device, 1);
...
// 在另一个地方添加驱动
platform_driver_register(&foo_driver);
随后驱动中的foo_probe()函数将被调用。
有不少代码,driver定义在它驱动目录下的文件里,device或许又定义在板级初始化目录下的文件里面,显得相当随心所欲。如今内核中这种代码也还存在,比方说omap使用了plat_nand设备:drivers/mtd/nand/plat_nand.c里注册驱动,arch/arm/mach-omap1/board-h2.c里面定义了nand flash的分区信息,并注册设备。
ARM架构片子浩如烟海,而且外设基本上都是平台设备,这导致内核里板级初始化部分相当混乱,充斥着长达数万行的静态声明的结构体和函数,又多又杂。这令Linus本人忍无可忍,终于在2011年3月17日将ARM社区臭骂一顿,斥其为痔疮(a f**king pain in the ass)。经过激烈的讨论,ARM从内核3.x之后便引入设备树来代替代码里面的平台设备了。。。
如何刻画一个设备?
现在我们要用另一种机制来代替平台设备。它简单明了,并且运行时转化为平台设备。
一个设备就是一个对象,世间万物都是对象。每个对象拥有一系列属性,属性即是名和值的对应;现在不想声明类而直接把对象表达出来。
可选用的语言
假若我们要表达一个名字为”serial1”,波特率为115200的串口,当然现实世界的串口属性远不止这些,还有它寄存器组的地址、中断源、DMA通道、时钟源等等。
如果直接用c语言数据结构来表示的话,显然就要先声明一个类再实例化:
struct usart_struct {
const char *name;
unsigned baudrate;
}
usart = {
.name = "serial1",
.baudrate = 115200,
};
因为设备实在太千奇百怪多种多样了,如果每一种芯片的外设都这么搞的话,那代码就相当臃肿了。其实不少语言都能直接随心所欲地定义对象,它们可有两种风格:
- 标签式的风格,标签接标签,标签套标签。如XML:
<usart> <name>serial1</name> <baudrate>115200</baudrate> </usart> - 数据结构式的风格。如json:
{ "usart": { "name": "serial1", "baudrate": 115200 } }
其实,还真有一些工程的设备树就是json,XBoot就是这样。。。
Linux内核中,我们会用设备树来描述,其文件后缀是dts:
/ {
usart:serial1@0 {
baudrate = <115200>;
};
};
看上去像极了json,因为它们都是数据结构式的风格。其实内核编译dts之前先过一遍c预处理器,所以可以使用各种宏定义,包含头文件等等。
除了单纯刻画出对象的属性,还得表达不同对象之间的关系。对于硬件设备而言可以有以下的例子:
串口和时钟管理器这两个设备体现了依赖关系(dependency):串口依赖于时钟管理器产生时钟,初始化串口之前必须初始化时钟,初始化完时钟之后串口一般就不必理会时钟了;串口和串口对应的GPIO体现了聚合关系(aggregation):串口可以包含一些GPIO,但是这些GPIO不依赖串口而存在(或者说这些GPIO还可以用于其他的外设),初始化时并不强制要求谁先谁后;串口等一系列外设和SOC芯片体现了组合关系(composition):一系列外设组合成为SOC芯片;串口和DMA这两个设备体现的是一种比较通用的关联关系(association):它们是独立的两个设备,并且相互知道对方的存在;
如果要表达组合关系这种强烈的整体和局部的关系,那么直接把小的一方定义在大的一方之内就行了。但是如果两个对象比较独立,它们之间的关系就没有整体和局部那么的强烈,那么就需要有一个表达引用的语法,即在一个对象中去引用另一个对象,此时单纯的XML或者json就表达不出来了;而dts就可以表达出来。
设备树基本语法
一张图就够了: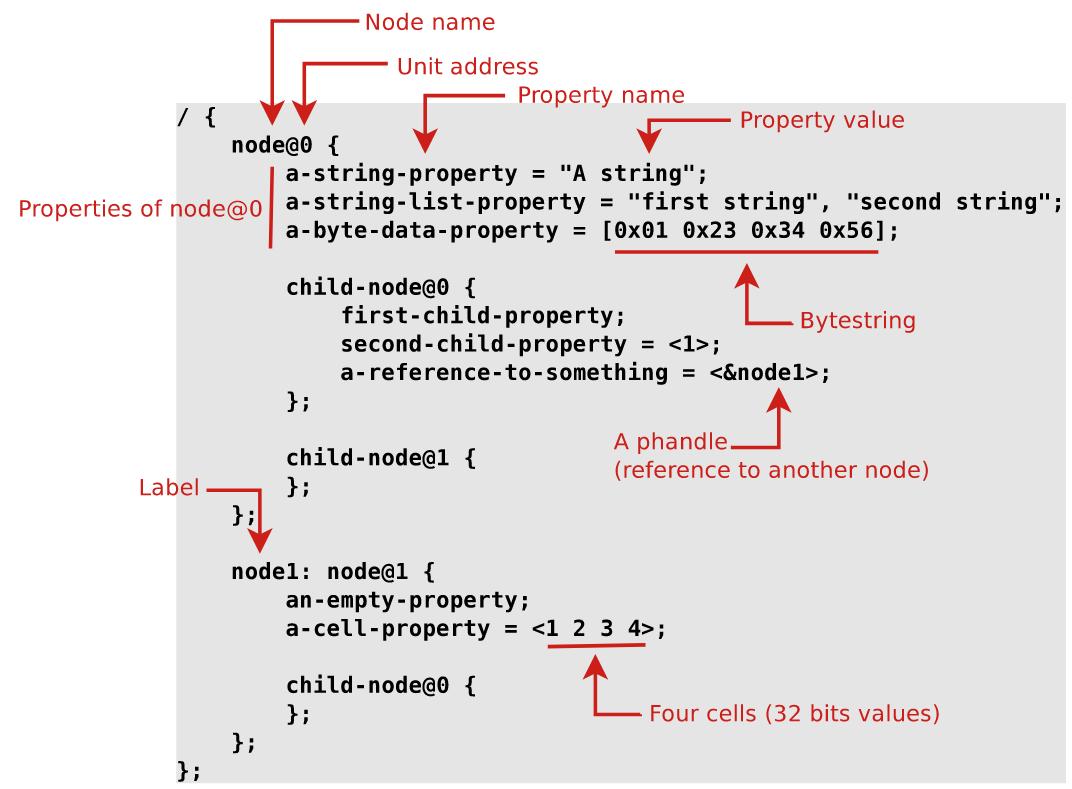
关注点是,
- 语句末要加分号
- 在哪里定义该节点的名字(Node name,在花括号之前,label之后)
- 在哪里定义该外设寄存器组的地址(Unit address,@符号)
- 属性名和属性值怎么定义(Property name和Property value,等于号来连接)
- 布尔属性(没有写值,仅表示这个属性声明与否)
- 数组怎么定义(a-string-list-property,用逗号分割的值)
- 一个属性有多个值该怎么定义(a-cell-property,尖括号中空格分隔的值)
- 标号怎么定义(Label,节点名字之前,用冒号)
- 怎么引用别的节点(phandel,&符号)
dts文件里面的节点里,一系列同名的节点描述的都是同一个对象,它们的属性相互叠加,若有冲突,则以最后出现的描述为准,是谓“后来居上”。比方说在靠前的地方这样描述这个串口:
/ {
soc {
...
serial@40011000 {
status = "disabled";
dma-names = "rx", "tx";
...
};
};
};
然后在靠后的地方又这样描述一遍:
/ {
soc {
// 记得要重新画一次设备树,然后
// 在相同的枝干下面写同名节点
serial@40011000 {
status = "okay";
};
};
};
最后生成的效果是:
/ {
soc {
...
serial@40011000 {
status = "okay";
dma-names = "rx", "tx";
...
};
};
};
注意到,status属性被改为okay了。
特别要强调的是,如果要在两个文件里面这样干,那么两个文件里面都得画上结构相同的设备树,然后在相同的枝干上写同名的节点,这才有效。就像上面例子中画了两次设备树,在根节点下soc节点下重写了serial节点。这显然很麻烦。不过可以使用标号和引用来简化。
还有这种操作:拿STM32的设备树作为例子:
在arch/arm/boot/dts/stm32f429.dtsi里面这样定义串口:
/ {
soc {
...
// 跟上面相比,加了标号
usart1: serial@40011000 {
status = "disabled";
dma-names = "rx", "tx";
...
};
};
};
然后在arch/arm/boot/dts/stm32f429i-eval.dts里面,include刚才那个设备树,接着使用标号改写这个节点:
#include <stm32f429.dtsi>
...
// 直接引用那个标号就行了
&usart1 {
status = "okay";
};
最后达到相同的效果。
设备树对应到驱动程序
设备树会展开为平台设备,但是它并不通过name字段去与平台驱动相匹配,而是通过compatible属性与driver中的compatible相匹配。compatible都是一个字符串。
比方说STM32F429的串口在设备树中这样写:
usart1: serial@40011000 {
compatible = "st,stm32-usart",
"st,stm32-uart";
...
};
在drivers/tty/serial/stm32-usart.c中这样定义compatible:
static const struct of_device_id stm32_match[] = {
{ .compatible = "st,stm32-usart", .data = &stm32f4_info},
{ .compatible = "st,stm32-uart", .data = &stm32f4_info},
{ .compatible = "st,stm32f7-usart", .data = &stm32f7_info},
{ .compatible = "st,stm32f7-uart", .data = &stm32f7_info},
{},
};
...
static struct platform_driver stm32_serial_driver = {
.driver = {
.of_match_table = of_match_ptr(stm32_match),
},
...
};
设备树和驱动中的compatible字段都可以不只有一个,只要任何一个字符串相同,就可以匹配上了。
注意到of_device_id列表里面,每一个compatible项目都对应了一个data成员。驱动匹配上设备后,可以顺藤摸瓜找到相关的data,从而在一个驱动程序里面实现多个相似设备的驱动。
“设备树绑定”,以及“设备树绑定”的文档
设备树中应该描述哪些属性,属性值应该怎么设置?写BSP的程序员可以自由去定义,然后通过一系列设备树相关接口找到设备树中设置的值。比方说STM32的串口:
usart1: serial@40011000 {
compatible = "st,stm32-usart",
"st,stm32-uart";
reg = <0x40011000 0x400>;
interrupts = <37>;
clocks = <&rcc 0 STM32F4_APB2_CLOCK(USART1)>;
dmas = <&dma2 2 4 0x400 0x0>,
<&dma2 7 4 0x400 0x0>;
dma-names = "rx", "tx";
pinctrl-0 = <&usart1_pins_a>;
pinctrl-names = "default";
status = "okay";
};
它有各种属性,驱动程序里逐个查找这些属性的配置,比方说:
- of_match_device()通过匹配
compatible,找到3.3中所述of_device_id表中对应项,以方便提取其对应的data,作为驱动程序里面自定义的私有数据。 - platform_get_resource()和devm_ioremap_resource()配对使用,提取出设备树节点的
reg属性。 - platform_get_irq()提取
interrupts属性。 - devm_clk_get()提取
clocks属性。 - dma_request_slave_channel()输入
dma-names里某一个字符串,查找出对应的dmas属性。比方说通过”rx”找到<&dma2 2 4 0x400 0x0>。
这些属性可能的配置,以及处理这些配置的代码,综合起来叫设备树绑定(devicetree bindings)。在源码Documentation/devicetree/bindings/目录下面罗列了一大堆描述设备树绑定的文档。
应该说,设备树绑定长什么样,这取决于程序员的设计;有不少属性的用途是“众所周知”的,比方说
- compatible属性用于匹配驱动
- reg属性用于描述改外设接口寄存器的地址空间
- pinctrl-0、pinctrl-names用于描述该外设对应到的GPIO
- status表示这个外设是否启用
有不少属性是该驱动所特有的,比方说,根据Documentation/devicetree/bindings/serial/st,stm32-usart.txt文档,还有一个布尔属性叫”st,hw-flow-ctrl”,表示是否启用USART的流控功能。
设备树复杂的地方并不在于它的语法,而恰恰在于设备树绑定。不同的程序员写出的设备树绑定不尽相同,同一个外设在不同芯片中的设备树绑定相差甚远,甚至同名的属性功效完全不同。最典型的例子就是pinctrl了,它管GPIO引脚复用;换一款芯片、换一个BSP,或许也得重新学习一遍它的pinctrl。。。
所以,设备树仿佛变成了最不具有可移植性的那部分了。Linus顺利地将ARM芯片的混乱性,从板级初始化程序中成功转嫁到设备树绑定中去了,然后他仿佛就不管后事了。。。这也为人所诟病:Thomas Petazzoni在2015年的ELC会议上抱怨说:不同内核里设备树绑定要保持可移植性,这简直是个神话。他说,很多厂商推出的系列芯片,它们的数据手册并不存在(doesn’t exist),以至于社区的工程师们要发挥想象力猜测它的功能;不少外设寄存器设计得相当傻逼(stupid),有很多神秘而唐突的使能位叫人捉摸不透,要维护这些驱动简直是折磨。他举出了Marvell和全志的芯片作为反面例子:这些芯片手册又冇,上流社会又要设备树绑定的移植性好;又举出Atmel芯片作为正面例子:Atmel的数据手册流传甚广,但是Atmel的维护者明确地声明:我的设备树绑定不能保证移植性。油管视频在此。
不管怎样,时至今日,ARM端的代码已经深刻地与设备树相耦合了。话说回来,设备树也是一个相当优雅的设计,或许这是应对ARM架构芯片纷繁复杂的驱动的最好解决方法了。。。
