应用程序需要内核提供各种服务才能运行,服务通过库以及相应的ABI(Application Binary Interface,应用程序二进制接口)来提供,比方说C库等。nuttx的应用程序可以内置在内核中(built-in),也可以与内核分开(separate),即运行外部可执行文件。目前它支持两种可执行文件:
ELF,就是Linux下标准的ELF可执行文件;NXFLAT,它是简化版的XFLAT;XFLAT原为UCLinux开发,特点在于体积小、可以就地运行(XIP);简化在于,NXFLAT不支持动态链接,不能导出符号表。
本文讨论如何为nuttx添加riscv的ELF支持,以及如何制作nuttx ELF应用程序。以下叙述适用于nuttx-7.25,nuttx还很年轻,即使是小版本之间的代码变动也可能会比较大。。
ELF简述
ELF的基本结构可参考SystemV ABI文档。简单说,从上到下依次是ELF头、程序头、段、段表。
ELF头记录基本信息,如该ELF的目标机器、ABI类型、入口地址、段表程序头等的偏移地址。ELF标准中里面的字段以e_作为前缀。程序头记录需要加载的内容,供ELF加载器操作:该加载的加载,该动态链接的动态链接等。Linux中可执行的文件都必须有程序头,可重定位的ELF则没有程序头。其字段以p_作为前缀。段里堆放着该文件的具体内容,需要结合最后面的段表才能分段解读。虽然大家都会很粗线条地将一个程序分为text段、data段等段,但是实际上段可以很随心所欲地设置,比方说- 在链接脚本里安排一个段,管它叫什么名字,然后在代码里面
__attribute__((section("xxx"))); - gcc的
-ffunction-sections和-fdata-sections,可以为每一个函数或者变量安排一个段; - objcopy的
--add-section可以手动添加一个段; - 有些病毒通过在ELF中注入自己的段来感染宿主
- 在链接脚本里安排一个段,管它叫什么名字,然后在代码里面
段表记录这些段的诸如起始地址、长度等信息。可重定位的ELF必须有段表,而可执行的ELF则不必有段表,虽然一般都会保留。其字段以sh_为前缀。每个段都有不同的功能,比方说text段就是机器码,data段是数据区,rela段指示重定位信息,symtab段是符号表,debug段指示源代码信息等。
readelf常用命令
xxxxxxxx-readelf是binutils的工具,用来查看ELF信息。有这些常用的命令:
-h查看ELF头-l查看程序头-S查看段表-s查看符号表-d查看动态链接的符号表-r查看重定位表-a统统看
下面摘录一个ELF头:
$ readelf -h /lib/x86_64-linux-gnu/ld-2.27.so
ELF 头:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
类别: ELF64
数据: 2 补码,小端序 (little endian)
版本: 1 (current)
OS/ABI: UNIX - System V
ABI 版本: 0
类型: DYN (共享目标文件)
系统架构: Advanced Micro Devices X86-64
版本: 0x1
入口点地址: 0x1090
程序头起点: 64 (bytes into file)
Start of section headers: 169232 (bytes into file)
标志: 0x0
本头的大小: 64 (字节)
程序头大小: 56 (字节)
Number of program headers: 7
节头大小: 64 (字节)
节头数量: 27
字符串表索引节头: 26
几种EFL
由EFL头部的e_type字段标明。值得关注的有这三种:
EL_REL,可重定位的ELF。gcc -c生成的中间文件.o就是这种类型,没有经过ld最终链接,是谓“可重定位”。另外Linux内核模块.ko文件也是这种类型,在insmod或者modprobe时候由加载器进行最终的链接。这种ELF没有程序头,有段表。EL_EXEC,可执行的ELF。gcc最终调用ld生成可执行的ELF。这种ELF必须要程序头来指示加载哪些部分。值得一提的是对于嵌入式工程来说编译得到一个ELF文件是“可执行”的,因为可以利用gdb通过各种gdb server、jtag bridge之类的工具连上板子,从而load程序。EL_DYN,动态链接文件。一般指gcc -shared生成的.so文件。动态链接的关键就在于导出符号表。虽然.ko和.so都要经过连接才会被执行,但是前者由Linux内核进行连接,后者由用户空间的动态连接器(一般名叫/lib/ld-linux.so什么的)进行连接。
nuttx的binary-loader
nuttx就用最直接的方式实现了外部程序的加载器,没什么花拳绣腿。
设计思想
- 为了支持多种可执行文件类型,就做成一个链表吧。每一种binfmt类型都需要在板极appinit里面注册。加载一个文件时候就沿着链表调它回调函数,直到有一个成功运行;
- 应用程序直接连接到内核,直接用内核的c库,没有额外的动态链接库。只需经过最简单操作就可执行的ELF当属可重定位的ELF了,于是nuttx就这么干——它的程序相当于Linux中
.ko文件的地位。因此nuttx就可以被称为所谓“模块化”了。
ELF代码跟踪
nuttx的一个基本规范是,将一个功能拆分成一个个小文件;这样既可以让代码好读也可以便于裁剪。ELF代码位于binfmt/libelf目录中,里面都是程序文件都只有几百行。
- 应用程序的入口:
sched/task/task_execv.c:execv(),随后进入binfmt/binfmt_exec.c:exec(); - 然后在文件系统中找到该文件:调用
binfmt/binfmt_loadmodule.c:load_module(),在该文件的load_absmodule()中遍历已经注册的binfmt,调用其load方法; - 对于ELF,则load方法为
binfmt/elf.c:elf_loadbinary():- 首先将该加载的部分加载到内存里:
binfmt/libelf/libelf_load.c:elf_load(); - 然后进行重定位:
binfmt/libelf/libelf_bind.c:elf_bind()
- 首先将该加载的部分加载到内存里:
- 加载完成,就可以跳到程序入口了。
riscv重定位
重定位部分是依赖架构的:它需要根据重定位的地址,修改对应位置的机器码从而让它可以正确运行。nuttx的重定位竟然放在libc中。。。具体在libs/libc/machine中实现。
重定位符号
代码里的常量在编译时候就能够确定,并不需要重定位。该工程内部的函数变量都是可确定的,也不需要重定位。ELF里需要重定位的是外部的变量、函数,本质上说就是地址,要重定位的地方就是一条未填入地址的用于寻址的机器码。重定位过程就是将那条指令抠出来然后填入正确的地址。这是架构相关的部分。
重定位ELF中每一个需要被重定位的段都配有一个相应的重定位段,如.text段配.rela.text。重定位段中的字段以r_为前缀。它就是一个表,有两种重定位段,在段表中标明:
SHT_REL,每个表项有两个字段,r_offset指出该指令的位置,r_info有一个字段是符号表(.symtab)的索引;SHT_RELA,比SHT_REL类型多一个所谓“加数”r_addend,是符号的偏置,从符号表中得到符号后需要加上它。
ARM的ELF只有SHT_REL类型的重定位段,而riscv的ELF只有SHT_RELA类型的重定位段。x86就两者都有。
符号表.symtab专门存储该ELF中的符号信息,其中关键字段有:
st_shndx,正常的话是一个正整数,是段表的索引,因为不少符号值在某一个段中,比方说代码里面的字符串常量就存在.rodata段里。还有一些其他取值:SHN_UNDEF,定义为0,表示这个符号不在本ELF中;SHN_ABS,定义为0xfff1,表示一个绝对量(absolute value);SHN_COMMON,定义为0xfff2,表示一个还未分配空间的块。nuttx并不支持;gcc加参数-fno-common就可以不生成这种符号;
st_value,表示该符号在st_shndx那个段的偏移量。st_name,该符号的名字,是.strtab字符串表的的索引。如果符号未定义,需要通过符号名从外部符号表里面搜索。
字符串表.strtab堆放着一批字符串,以0结尾。这些字符串并不是给程序用的,而是给装载器、调试器之类的工具用的,因此装载器并不会在内存中给它分配空间。程序用到的字符串一般存在.rodata段。
可以用readelf -p .strtab xxxx.elf来查看字符串表。
通常情况下要resolve一个在本ELF中符号: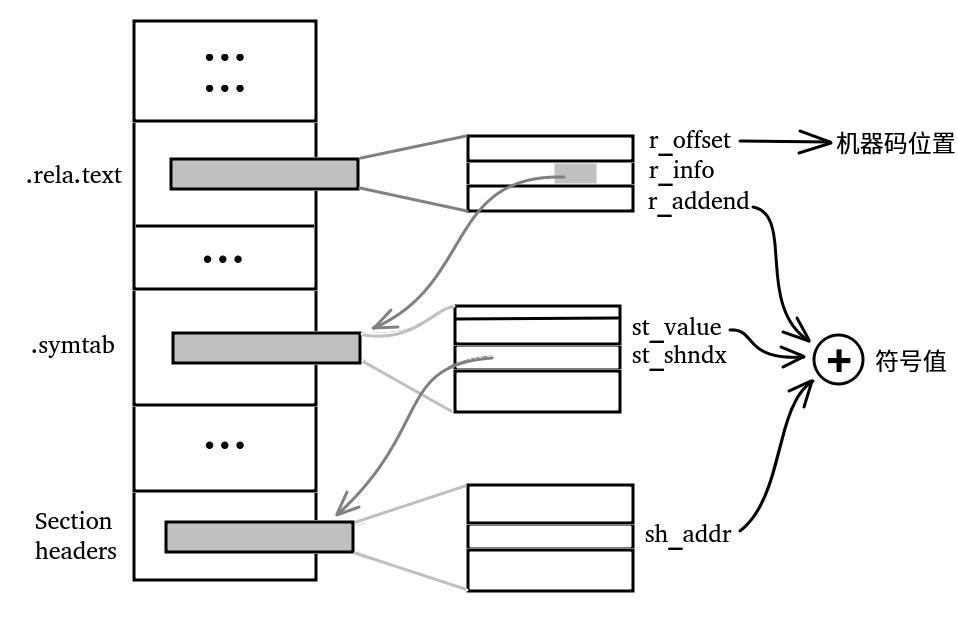
如果本ELF符号表中没有,那么通过.symtab从.strtab中找到符号名称,从系统的符号表中找。高效率的系统会将符号表设计为一个哈希表,静态的哈希表还可以通过gperf来生成“perfect”的哈希表,例如编译器、解释器等要通过字符串识别一个个token,而关键字都是确定的,这种情况最适合用gperf。而nuttx实现太简单了,它就是只支持静态的符号表,而且仅仅通过遍历来寻找符号。。
riscv重定位类型
根据riscv的ABI文档,有那么几十种重定位类型;而riscv的Linux内核模块装载器只实现了其中的少部分。因为nuttx的ELF相当于Linux内核.ko的地位,而且不支持动态链接,所以需要实现的就更少了;而最关键最常用的也只有寥寥几种。
rv32-I基本指令集有四种编码类型的指令:R、I、S、U:
其中I、S、U都能编码立即数,前两者能编码12位,后者能编码20位。
rv32的基本指令集都是32位定长的。如果要加载一个32立即数,riscv不是像ARM那样弄一个“文字池(literal pool)”然后从里面load,而是直接把立即数编码在两条指令中分两次加载。这样的好处是指令都在流水线上,不需要等待访存操作。所以很多重定位类型都是成双成对的。下面分别讨论:
- C语言里面引用全局变量、字符串常量这种地址固定(absolute address)的变量,就是
R_RISCV_HI20配R_RISCV_LO12_I或R_RISCV_LO12_S; - C语言里面调一个函数,函数地址是PC相关的(PC-relative call),由
auipc和jalr来实现。这时auipc之后一定是jalr,这种情况就是R_RISCV_CALL; - 循环、条件跳转等,用到
beq、bne等指令,需要有一个PC相关的偏移量,就是R_RISCV_BRANCH; - 用压缩指令集(gcc参数是
-mrvc。pulpino就支持)时候,各种条件非条件跳转,有R_RISCV_RVC_BRANCH、R_RISCV_RVC_JUMP等; - 还有一些不太常用的类型:
- 汇编里引用一个相对PC指针(PC-relative reference)的值,一般是
la伪指令展开的结果(有这样的用例:我想在某处调用一个子程序,但是子程序返回到另一个地方。那么我就la返回地址。。),则是R_RISCV_PCREL_HI20配R_RISCV_PCREL_LO12_I或R_RISCV_PCREL_LO12_S; - 汇编里调用本文件的子程序,用
jal指令调到子程序的标号那里。就是R_RISCV_JAL; - 还有直接操作符号的,如
R_RISCV_RELAX保持符号值不变、R_RISCV_32直接改32位数、R_RISCV_ADD32/R_RISCV_SUB32对那个32位数作加减。这些一般用于对debug段的重定位。
- 汇编里引用一个相对PC指针(PC-relative reference)的值,一般是
需要添加的代码
- nuttx里的ELF加载器基本上是给ARM做的,而ARM只有
SHT_REL类型的重定位,于是SHT_RELA类型的重定位就根本没有实现。。所以首先要依葫芦画瓢实现RELA的函数; - 添加
libs/libc/machine/riscv目录:- 根据上文3-2实现
arhc_elf.c; - 添加Makefile和Kconfig;
- 根据上文3-2实现
制作nuttx可运行的ELF
参考资料:elf-addon
Linux的xxx-linux-gcc工具链可以直接生成对应平台下的ELF文件;UCLinux的工具链xxx-uclinuxeabi-gcc可以直接生成可在UCLinux下运行的flat文件,并附带一个后缀为.gdb的ELF文件用于调试;这些ELF文件都是可执行类型的。
但是nuttx的应用程序是可重定位类型的,就是.o级别的,因此其实并不需要xxx-nuttx-gcc,直接用xxx-none-gcc、xxx-unknown-gcc就可以了。另外nuttx的buildroot制作的xxx-nuttx-gcc其实跟Linux、UCLinux的并不是一回事,也不能不加参数一步到位生成可执行的ELF。这时我们应该显示地先编译再链接,链接时候需要加参数-r以告诉ld要生成relocatable的ELF。
作为例子,假设有这样一个c应用程序:
// hello.c
#include <stdio.h>
int main(void)
{
printf("Hello from Add-On Program!\n");
return 0;
}
该程序中printf是C库函数,在nuttx内核提供的C库里。所以问题就是要将找到printf符号。如果用的是工具链里的C库(riscv32-unknown-elf-用的是newlib),那上面的printf有可能会被编译器解释为putc。如果用nuttx打包的头文件的话就还是printf。这个程序的重定位表有以下表项:
偏移量 信息 类型 符号值 符号名称 + 加数
00000000 0000071a R_RISCV_HI20 00000000 .LC0 + 0
00000006 0000071b R_RISCV_LO12_I 00000000 .LC0 + 0
0000000c 00000b12 R_RISCV_CALL 00000000 printf + 0
其中前两个是字符串常量"Hello from Add-On Program!\n",最后一个是printf符号。
内核没有符号表:直接链到固定地址
由于并没有外部符号表,因此printf不能是UND符号。例子中用了两次链接。第一次将所有编译的.o链接为一个可重定位的文件(相当于archive了一次);然后第二次链接,填入所有未定义符号。
编译完nuttx内核,就会生成一个System.map文件,里面列举了所有全局变量和函数的地址,其中就包括C库的函数。我们找到printf的地址,假设它是0x23015bc2。可以在ld script里面加一句话:printf=0x23015bc2;,也可以为ld加参数--defsym=printf=0x23015bc2。这样就能消掉printf的未定义。
printf未定义时,符号表里是这样的:
11: 00000000 0 NOTYPE GLOBAL DEFAULT UND printf
第二次链接之后,printf被resolved成一个absolute的值0x23015bc2。
8: 23015bc2 0 NOTYPE GLOBAL DEFAULT ABS printf
内核有符号表:根据静态符号表链入内核
这时就允许printf是UND符号了,因为有外部符号表。但是这个符号表需要写死在内核里。如果只需要printf的话可以这样写一个数组:
#include <stdio.h>
#include <nuttx/binfmt/symtab.h>
const struct symtab_s g_symtab[] =
{
{"printf", (FAR void *)printf}
};
int g_nsymbols = 1;
其中g_symtab、g_nsymbols都是在Kconfig里预定义好的符号。。。会在binfmt/binfmt_execsymtab.c里被引用。
nuttx也有工具去生成符号表,这个工具提供了源码:tools/mksymtab.c和tools/cvsparser.c可制作出mksymtab工具,它输入一个.csv文件,输出一个.c文件。.csv文件在源码里就有,它枚举了函数名、参数等信息。tools/README.txt里建议这样生成符号表数组:
$ cd nuttx/tools
$ cat ../syscall/syscall.csv ../libs/libc/libc.csv | sort > tmp.csv
$ ./mksymtab tmp.csv tmp.c
然后将符号表加入源码中编译即可。不过源码中提供的csv文件有点问题,有些函数还没有实现,需要一个个去除。。
ELF程序可以放在一张SD卡里面,然后执行: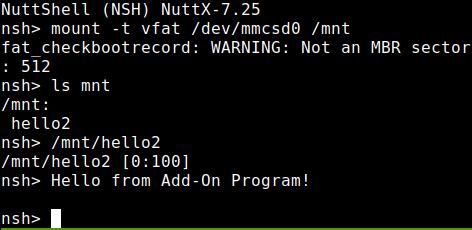
nuttx内核打包
可以将nuttx的头文件和静态链接库打包出去制作SDK。
$ make export
它将所有头文件打包,包括arch级以及板极的头文件,加上两个archives:libnuttx.a和libapps.a。头文件可以用于制作xxx-nuttx-gcc工具链;利用这个SDK可以对固件做二次开发。可参考Building NuttX with Applications Outside of the Source Tree,以及Using NuttX as a library。
