对于搞Cortex M系列mcu开发的人来说,hardfault这种鬼东西,不遇到还好,倘若不幸遇到了,复位一下,瞎调一下,左右修补,或许碰巧就消除了。但是靠人品毕竟不是长久之计。下面记录我调试hardfault的一些简单的经验。
hardfault来源
Cortex M3、M4的向量表中,3号异常是HardFault;接下来三个异常是MemFault、BusFault、UsageFault。发生了hardfault,基本是因为后面三个异常上访来的。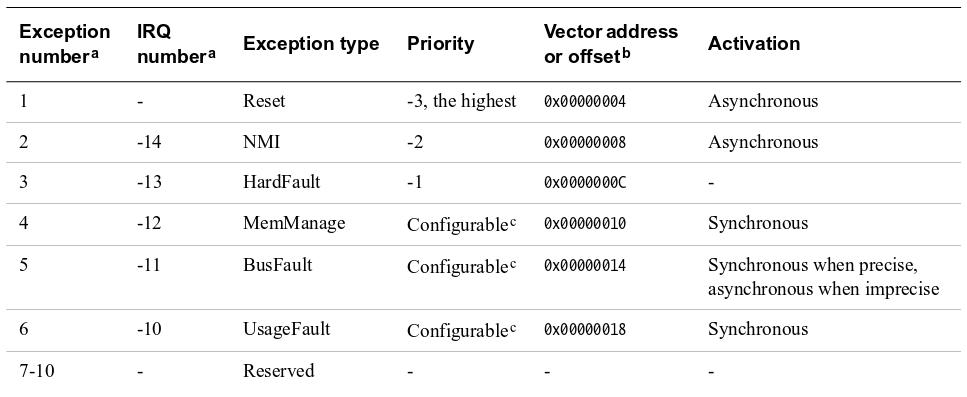
手册上的向量表
(按照他们的意思,异常与中断是两个概念,中断专指外设产生的中断,中断是一种异常)
MemFault是由MPU(内存保护模块)产生的。对于用到MPU的工程来说必定写好了MemFault处理函数,不应该由它上访;BusFault,CPU访问存储器出错时发生总线错误。主要就是读写数据失败。这是最常碰到的一类错误,鉴于不少单片机工程师基本不写busfault处理函数,我碰到的基本上所有hardfault都是由总线错误引起的。。。UsageFault,CPU执行到非法指令,或者处于非法的模式下面。比方说在没有fpu的情况下访问fpu,没有协处理器的情况下访问协处理器;更常见的情况是PC最低位莫名其妙的变成了0进入ARM模式,而Cortex M只有thumb模式,从而出错。碰到了用法错误,如果不是自己作死(比方说写错汇编),基本上就是碰到了编译器的bug。。。
碰到hardfault
此时板子上应当连着一个调试器。。。
(对于Cortex M0,我试过在它正在跑的时候用jlink连它,无论当时它还是不是在欢快地运行,一连就hardfault;以我拙见,如果板子确定是由于hardfault死掉了,那要从一开始就连着调试器,然后复现状况)
看哪个fault引起的
先看Hardfault Status Register,地址0xE000ED2C。看第30位是否为1,验证一下它是不是上访而来的。
然后关注总线错误。看BusFault Status Register,地址0xE000ED29;这是一个8位寄存器,重点关注第1、2位:
就看它是不是精确的总线错误;PRECISE的话,0xE000ED38地址的寄存器BusFault Address Register记录了哪里而引发的错误;IMPRECISE的话就有点麻烦了。
如果用keil,则可以打开 Peripherals -> Core Peripherals -> Fault Reports 窗口直观地看哪个fault: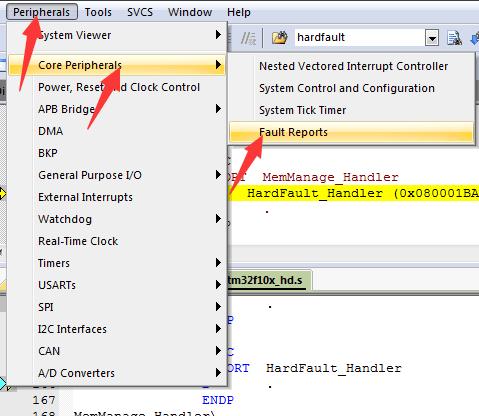
如果是命令行工具,JLinkExe命令行下面用mem8、mem32来看;gdb下面则用x命令来看。
看堆栈
直接在CPU寄存器那里看两个堆栈指针。
首先,堆栈应该在合法的RAM那里,比方说0x20000000后面的几十上百k处,又比方说初始化了片外RAM之后在片外RAM处。还要看堆栈是否溢出。
如果SP明显不合法的话,那接下来就要检查代码写的对不对,有没有死递归,链接脚本有没有写对(比方说移植某些项目时候,代码原本跑在内存里面,然后转片内flash了,也没有把堆栈段放好),等等。
如果判断是堆栈溢出了,一般来说跑裸机的话没有写堆栈溢出的保护措施,以至于stack段践踏了heap段,甚至践踏了data段,以致于破坏了一些全局变量,那就需要增加堆栈的大小;对于keil工程,在那个startup_xxxxx.s里面改stack和heap的大小;对于makefile工程,就在链接脚本里面改(不过一般都会设到SRAM的最末端)。堆栈溢出可能造成任何fault。
如果堆栈安好,那问题就出在别处;此时堆栈里面记录了出事地点,还有一些寄存器的值: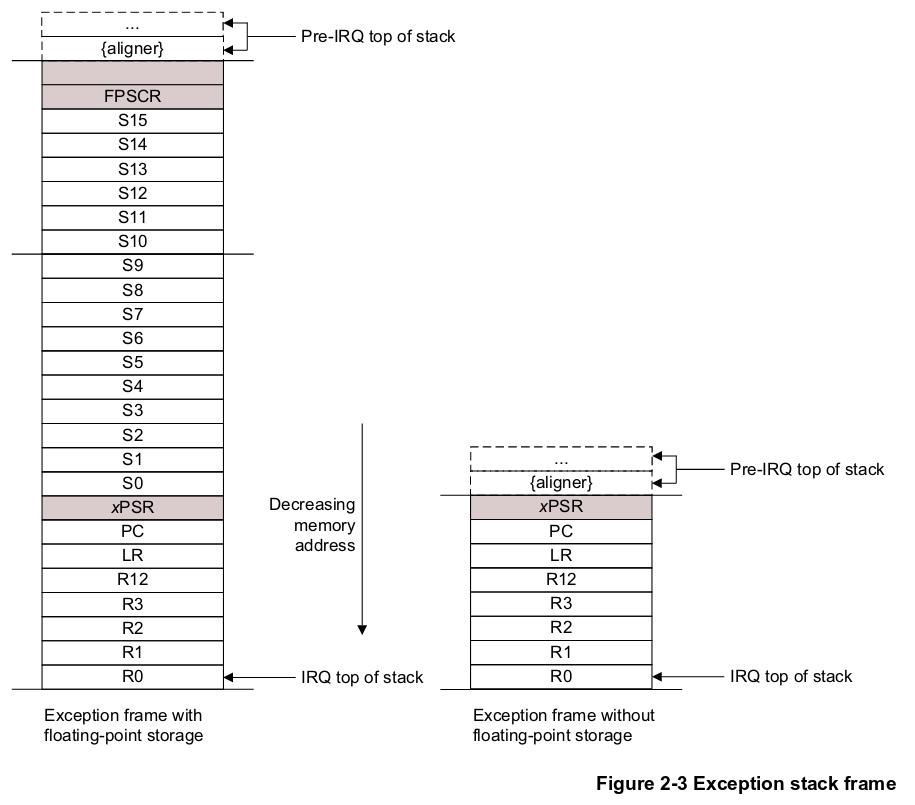
其中,第7个int是出事时候的PC值,第6个int是出事时候的LR值(即调用者)。通过堆栈里的PC值可以查到出事的那行代码:gcc工具链中的addr2line就在专门干这个的;keil的话在反汇编窗口,右键,show disassembly at address,输入那个地址即可。
一般来说,看到哪一行代码出事,差不多就解决了问题,对于PRECISE的总线错误的话,0xE000ED38地址处的寄存器BusFault Address Register记录了哪里而引发的错误,此时检查一些变量,检查一下野指针。
应对IMPRECISE BusFault
以我的经验,非精确的总线错误基本上是因为写了片内flash区域。不信你试试给const char*的字符串赋值(强转一下)。但是出现非精确总线错误时候并不知道CPU已经执行了多少指令,没有哪个寄存器可以定位出错地点。
但是对于Cortex M3、Cortex M4来说,IMPRECISE的错误可以转化为PRECISE的错误!将地址0xE000E008处的寄存器Auxiliary Control Register的第1位DISDEFWBUF置1,取消写缓冲,于是内核就会老老实实等待每个写访问完成之后再继续运行,据说就不会产生IMPRECISE总线错误了。
一个例子
C语言里面指针跟数组名不是一回事。指针是变量,但是数组名就不是变量。虽然有时候混用并没有语法错误,但是运行时候就不同了。。。
假设我在str.c里面定义一个buff数组:
char buff[10];
然后我在main.c里面才用到它;我声明它为一个指针,并且这样用它:
extern char *buff;
int main(void)
{
buff[0] = 'a';
while(1);
return 0;
}
没语法错误啊,buff不管是一个数组名,还是一个指针,buff[0]这样引用第0个元素怎么都是对的。
然后我们烧进板子里面,跑一下,结果它最后卡在HardFault_Handler里面了。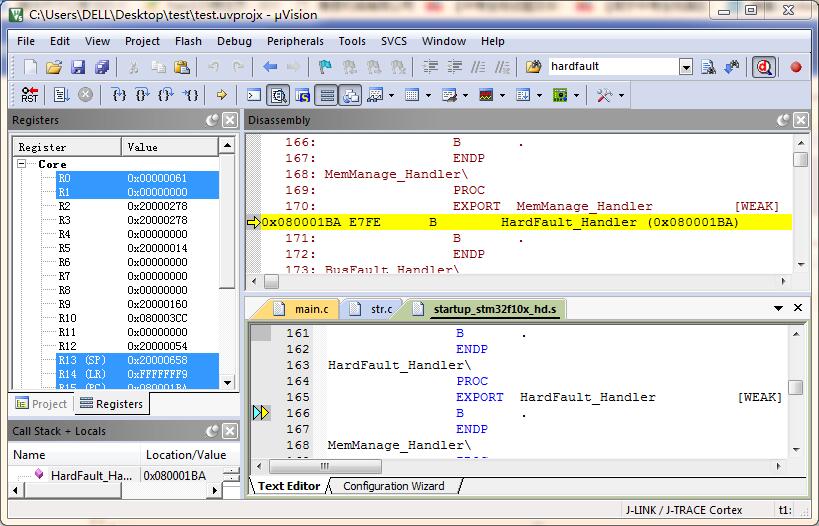
然后看fault report,发现居然还是IMPRECISE的总线错误。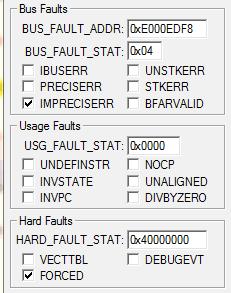
程序非常简单,错误肯定出在main.c第5行buff[0] = 'a'这里。为什么呢?
我们来看看反汇编: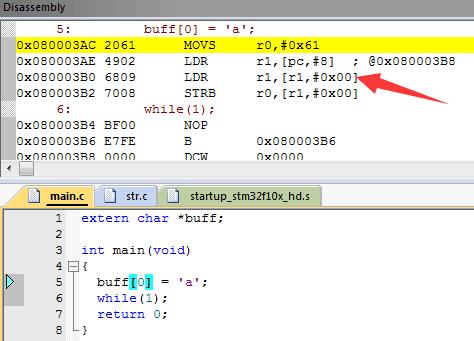
因为指针是变量,但凡变量都客观存在,都有一块实际的内存;引用一个变量要两步,先找到它的地址,再通过地址找它;所以若要给指针指向的值赋值,就要:取指针地址,通过指针地址取指针值,用寄存器寻址方式去赋值,所以它有两次LDR。
但是数组名不是变量,所以它不客观存在,它没有地址,引用它,就一步到位找到它的值了。
因为二者不是同一类型,所以如果你在同一个文件里面这样写的话就会出编译错误,说buff重复定义:
char buff[10];
extern char *buff;
将定义和声明分开在不同的文件里面写的确是良好的工程习惯。但是上面的东西分开来写之后,编译器先逐个文件编译再链接,每个c文件都没有语法错误;而链接器并不识别类型,只根据名字将符号组合在一起,所以也发现不了这样的错误。然后程序员就愉快地以为天下无事了。
然后在运行时候,因为多了一次LDR命令,导致它将buff指向的值当做了buff本身,而现在这个值是0x00000000,然后将’a’写到0x00000000处,对STM32来说这是片内flash的地址。另外Cortex M将这个地址视为可写的,并不会立即出错;等到STM32的flash控制器发现flash没有解锁而写入了,就触发一个总线错误,然而此时CPU不知道已经跑了多久了。
如果把声明为数组:
extern char buff[];
那么反汇编就没事:![char buff[]的反汇编](/hardfault/asm2.jpeg)
自然运行也没事了。
在一个大工程里面找这样的编译器发现不了的错误,源自于某程序员一时手抖的错误,解决办法那么简单的错误,然而那么难以定位的错误,而且责任又那么难以追究的错误,要多坑有多坑。
编写hardfault处理函数
hardfault处理函数的手段十分有限,基本上只能干两种事:上报错误,重启。
对于裸机来说,出现了hardfault就意味着代码有严重错误,肯定不能指望hardfault来恢复些什么东西的,hardfault就是用来给你调试的,如果实在调不出来,为保证系统持续工作,你应该在出现hardfault之前重启系统。
如果上了操作系统,那就是你某个任务出现了严重错误,应该想办法将错误print到上位机以便调试。可选的方式是,将错误信息复制出去,消掉错误状态位,然后在别的地方上报错误,最后想办法重启任务,以便继续工作。
更详细的方案,请参考《ARM Cortex-M3 权威指南》附录E,以及别的某某权威指南。
